Creating The “Moving Highlight” Navigation Bar With JavaScript And CSS
Blake Lundquist 2025-06-11T13:00:00+00:00
2025-06-20T10:32:35+00:00
I recently came across an old jQuery tutorial demonstrating a “moving highlight” navigation bar and decided the concept was due for a modern upgrade. With this pattern, the border around the active navigation item animates directly from one element to another as the user clicks on menu items. In 2025, we have much better tools to manipulate the DOM via vanilla JavaScript. New features like the View Transition API make progressive enhancement more easily achievable and handle a lot of the animation minutiae.
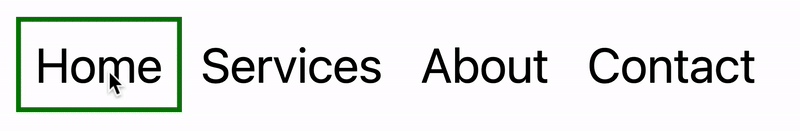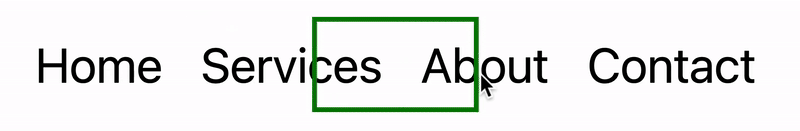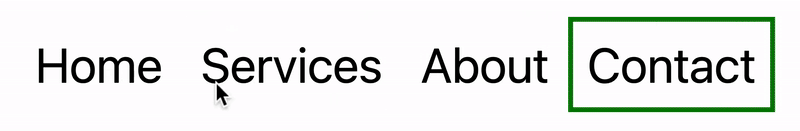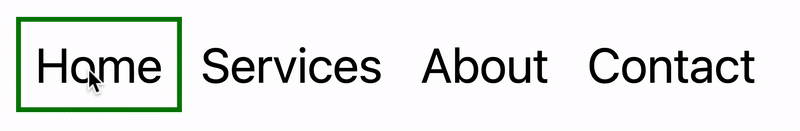
In this tutorial, I will demonstrate two methods of creating the “moving highlight” navigation bar using plain JavaScript and CSS. The first example uses the getBoundingClientRect method to explicitly animate the border between navigation bar items when they are clicked. The second example achieves the same functionality using the new View Transition API.
The Initial Markup
Let’s assume that we have a single-page application where content changes without the page being reloaded. The starting HTML and CSS are your standard navigation bar with an additional div element containing an id of #highlight. We give the first navigation item a class of .active.
See the Pen [Moving Highlight Navbar Starting Markup [forked]](https://codepen.io/smashingmag/pen/EajQyBW) by Blake Lundquist.
For this version, we will position the #highlight element around the element with the .active class to create a border. We can utilize absolute positioning and animate the element across the navigation bar to create the desired effect. We’ll hide it off-screen initially by adding left: -200px and include transition styles for all properties so that any changes in the position and size of the element will happen gradually.
#highlight {
z-index: 0;
position: absolute;
height: 100%;
width: 100px;
left: -200px;
border: 2px solid green;
box-sizing: border-box;
transition: all 0.2s ease;
}
Add A Boilerplate Event Handler For Click Interactions
We want the highlight element to animate when a user changes the .active navigation item. Let’s add a click event handler to the nav element, then filter for events caused only by elements matching our desired selector. In this case, we only want to change the .active nav item if the user clicks on a link that does not already have the .active class.
Initially, we can call console.log to ensure the handler fires only when expected:
const navbar = document.querySelector('nav');
navbar.addEventListener('click', function (event) {
// return if the clicked element doesn't have the correct selector
if (!event.target.matches('nav a:not(active)')) {
return;
}
console.log('click');
});
Open your browser console and try clicking different items in the navigation bar. You should only see "click" being logged when you select a new item in the navigation bar.
Now that we know our event handler is working on the correct elements let’s add code to move the .active class to the navigation item that was clicked. We can use the object passed into the event handler to find the element that initialized the event and give that element a class of .active after removing it from the previously active item.
const navbar = document.querySelector('nav');
navbar.addEventListener('click', function (event) {
// return if the clicked element doesn't have the correct selector
if (!event.target.matches('nav a:not(active)')) {
return;
}
- console.log('click');
+ document.querySelector('nav a.active').classList.remove('active');
+ event.target.classList.add('active');
});
Our #highlight element needs to move across the navigation bar and position itself around the active item. Let’s write a function to calculate a new position and width. Since the #highlight selector has transition styles applied, it will move gradually when its position changes.
Using getBoundingClientRect, we can get information about the position and size of an element. We calculate the width of the active navigation item and its offset from the left boundary of the parent element. Then, we assign styles to the highlight element so that its size and position match.
// handler for moving the highlight
const moveHighlight = () => {
const activeNavItem = document.querySelector('a.active');
const highlighterElement = document.querySelector('#highlight');
const width = activeNavItem.offsetWidth;
const itemPos = activeNavItem.getBoundingClientRect();
const navbarPos = navbar.getBoundingClientRect()
const relativePosX = itemPos.left - navbarPos.left;
const styles = {
left: `${relativePosX}px`,
width: `${width}px`,
};
Object.assign(highlighterElement.style, styles);
}
Let’s call our new function when the click event fires:
navbar.addEventListener('click', function (event) {
// return if the clicked element doesn't have the correct selector
if (!event.target.matches('nav a:not(active)')) {
return;
}
document.querySelector('nav a.active').classList.remove('active');
event.target.classList.add('active');
+ moveHighlight();
});
Finally, let’s also call the function immediately so that the border moves behind our initial active item when the page first loads:
// handler for moving the highlight
const moveHighlight = () => {
// ...
}
// display the highlight when the page loads
moveHighlight();
Now, the border moves across the navigation bar when a new item is selected. Try clicking the different navigation links to animate the navigation bar.
See the Pen [Moving Highlight Navbar [forked]](https://codepen.io/smashingmag/pen/WbvMxqV) by Blake Lundquist.
That only took a few lines of vanilla JavaScript and could easily be extended to account for other interactions, like mouseover events. In the next section, we will explore refactoring this feature using the View Transition API.
Using The View Transition API
The View Transition API provides functionality to create animated transitions between website views. Under the hood, the API creates snapshots of “before” and “after” views and then handles transitioning between them. View transitions are useful for creating animations between documents, providing the native-app-like user experience featured in frameworks like Astro. However, the API also provides handlers meant for SPA-style applications. We will use it to reduce the JavaScript needed in our implementation and more easily create fallback functionality.
For this approach, we no longer need a separate #highlight element. Instead, we can style the .active navigation item directly using pseudo-selectors and let the View Transition API handle the animation between the before-and-after UI states when a new navigation item is clicked.
We’ll start by getting rid of the #highlight element and its associated CSS and replacing it with styles for the nav a::after pseudo-selector:
- #highlight {
- z-index: 0;
- position: absolute;
- height: 100%;
- width: 0;
- left: 0;
- box-sizing: border-box;
- transition: all 0.2s ease;
- }
+ nav a::after {
+ content: " ";
+ position: absolute;
+ left: 0;
+ top: 0;
+ width: 100%;
+ height: 100%;
+ border: none;
+ box-sizing: border-box;
+ }
For the .active class, we include the view-transition-name property, thus unlocking the magic of the View Transition API. Once we trigger the view transition and change the location of the .active navigation item in the DOM, “before” and “after” snapshots will be taken, and the browser will animate the border across the bar. We’ll give our view transition the name of highlight, but we could theoretically give it any name.
nav a.active::after {
border: 2px solid green;
view-transition-name: highlight;
}
Once we have a selector that contains a view-transition-name property, the only remaining step is to trigger the transition using the startViewTransition method and pass in a callback function.
const navbar = document.querySelector('nav');
// Change the active nav item on click
navbar.addEventListener('click', async function (event) {
if (!event.target.matches('nav a:not(.active)')) {
return;
}
document.startViewTransition(() => {
document.querySelector('nav a.active').classList.remove('active');
event.target.classList.add('active');
});
});
Above is a revised version of the click handler. Instead of doing all the calculations for the size and position of the moving border ourselves, the View Transition API handles all of it for us. We only need to call document.startViewTransition and pass in a callback function to change the item that has the .active class!
Adjusting The View Transition
At this point, when clicking on a navigation link, you’ll notice that the transition works, but some strange sizing issues are visible.

This sizing inconsistency is caused by aspect ratio changes during the course of the view transition. We won’t go into detail here, but Jake Archibald has a detailed explanation you can read for more information. In short, to ensure the height of the border stays uniform throughout the transition, we need to declare an explicit height for the ::view-transition-old and ::view-transition-new pseudo-selectors representing a static snapshot of the old and new view, respectively.
::view-transition-old(highlight) {
height: 100%;
}
::view-transition-new(highlight) {
height: 100%;
}
Let’s do some final refactoring to tidy up our code by moving the callback to a separate function and adding a fallback for when view transitions aren’t supported:
const navbar = document.querySelector('nav');
// change the item that has the .active class applied
const setActiveElement = (elem) => {
document.querySelector('nav a.active').classList.remove('active');
elem.classList.add('active');
}
// Start view transition and pass in a callback on click
navbar.addEventListener('click', async function (event) {
if (!event.target.matches('nav a:not(.active)')) {
return;
}
// Fallback for browsers that don't support View Transitions:
if (!document.startViewTransition) {
setActiveElement(event.target);
return;
}
document.startViewTransition(() => setActiveElement(event.target));
});
Here’s our view transition-powered navigation bar! Observe the smooth transition when you click on the different links.
See the Pen [Moving Highlight Navbar with View Transition [forked]](https://codepen.io/smashingmag/pen/ogXELKE) by Blake Lundquist.
Conclusion
Animations and transitions between website UI states used to require many kilobytes of external libraries, along with verbose, confusing, and error-prone code, but vanilla JavaScript and CSS have since incorporated features to achieve native-app-like interactions without breaking the bank. We demonstrated this by implementing the “moving highlight” navigation pattern using two approaches: CSS transitions combined with the getBoundingClientRect() method and the View Transition API.
Resources
getBoundingClientRect()method documentation- View Transition API documentation
- “View Transitions: Handling Aspect Ratio Changes” by Jake Archibald
(gg, yk)





 );
}
);
}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}