Many modern websites give users the power to set a site-specific color scheme preference. A basic implementation is straightforward with JavaScript: listen for when a user changes a checkbox or clicks a button, toggle a class (or attribute) on the element in response, and write the styles for that class to override design with a different color scheme.
CSS’s new :has() pseudo-class, supported by major browsers since December 2023, opens many doors for front-end developers. I’m especially excited about leveraging it to modify UI in response to user interaction without JavaScript. Where previously we have used JavaScript to toggle classes or attributes (or to set styles directly), we can now pair :has() selectors with HTML’s native interactive elements.
Supporting a color scheme preference, like “Dark Mode,” is a great use case. We can use a element anywhere that toggles color schemes based on the selected — no JavaScript needed, save for a sprinkle to save the user’s choice, which we’ll get to further in.
Respecting System Preferences
First, we’ll support a user’s system-wide color scheme preferences by adopting a “Light Mode”-first approach. In other words, we start with a light color scheme by default and swap it out for a dark color scheme for users who prefer it.
The prefers-color-scheme media feature detects the user’s system preference. Wrap “dark” styles in a prefers-color-scheme: dark media query.
Next, set the color-scheme property to match the preferred color scheme. Setting color-scheme: dark switches the browser into its built-in dark mode, which includes a black default background, white default text, “dark” styles for scrollbars, and other elements that are difficult to target with CSS, and more. I’m using CSS variables to hint that the value is dynamic — and because I like the browser developer tools experience — but plain color-scheme: light and color-scheme: dark would work fine.
:root {
/* light styles here */
color-scheme: var(--color-scheme, light);
/* system preference is "dark" */
@media (prefers-color-scheme: dark) {
--color-scheme: dark;
/* any additional dark styles here */
}
}
Giving Users Control
Now, to support overriding the system preference, let users choose between light (default) and dark color schemes at the page level.
HTML has native elements for handling user interactions. Using one of those controls, rather than, say, a
nest, improves the chances that assistive tech users will have a good experience. I’ll use a menu with options for “system,” “light,” and “dark.” A group of would work, too, if you wanted the options right on the surface instead of a dropdown menu.
System
Light
Dark
Before CSS gained :has(), responding to the user’s selected required JavaScript, for example, setting an event listener on the to toggle a class or attribute on or .
But now that we have :has(), we can now do this with CSS alone! You’ll save spending any of your performance budget on a dark mode script, plus the control will work even for users who have disabled JavaScript. And any “no-JS” folks on the project will be satisfied.
What we need is a selector that applies to the page when it :has() a select menu with a particular [value]:checked. Let’s translate that into CSS:
:root:has(select option[value="dark"]:checked)
We’re defaulting to a light color scheme, so it’s enough to account for two possible dark color scheme scenarios:
The page-level color preference is “system,” and the system-level preference is “dark.”
The page-level color preference is “dark”.
The first one is a page-preference-aware iteration of our prefers-color-scheme: dark case. A “dark” system-level preference is no longer enough to warrant dark styles; we need a “dark” system-level preference and a “follow the system-level preference” at the page-level preference. We’ll wrap the prefers-color-scheme media query dark scheme styles with the :has() selector we just wrote:
:root {
/* light styles here */
color-scheme: var(--color-scheme, light);
/* page preference is "system", and system preference is "dark" */
@media (prefers-color-scheme: dark) {
&:has(#color-scheme option[value="system"]:checked) {
--color-scheme: dark;
/* any additional dark styles, again */
}
}
}
Notice that I’m using CSS Nesting in that last snippet. Baseline 2023 has it pegged as “Newly available across major browsers” which means support is good, but at the time of writing, support on Android browsers not included in Baseline’s core browser set is limited. You can get the same result without nesting.
:root {
/* light styles */
color-scheme: var(--color-scheme, light);
/* page preference is "dark" */
&:has(#color-scheme option[value="dark"]:checked) {
--color-scheme: dark;
/* any additional dark styles */
}
}
For the second dark mode scenario, we’ll use nearly the exact same :has() selector as we did for the first scenario, this time checking whether the “dark” option — rather than the “system” option — is selected:
:root {
/* light styles */
color-scheme: var(--color-scheme, light);
/* page preference is "dark" */
&:has(#color-scheme option[value="dark"]:checked) {
--color-scheme: dark;
/* any additional dark styles */
}
/* page preference is "system", and system preference is "dark" */
@media (prefers-color-scheme: dark) {
&:has(#color-scheme option[value="system"]:checked) {
--color-scheme: dark;
/* any additional dark styles, again */
}
}
}
Now the page’s styles respond to both changes in users’ system settings and user interaction with the page’s color preference UI — all with CSS!
But the colors change instantly. Let’s smooth the transition.
Respecting Motion Preferences
Instantaneous style changes can feel inelegant in some cases, and this is one of them. So, let’s apply a CSS transition on the :root to “ease” the switch between color schemes. (Transition styles at the :root will cascade down to the rest of the page, which may necessitate adding transition: none or other transition overrides.)
Note that the CSS color-scheme property does not support transitions.
:root {
transition-duration: 200ms;
transition-property: /* properties changed by your light/dark styles */;
}
Not all users will consider the addition of a transition a welcome improvement. Querying the prefers-reduced-motion media feature allows us to account for a user’s motion preferences. If the value is set to reduce, then we remove the transition-duration to eliminate unwanted motion.
:root {
transition-duration: 200ms;
transition-property: /* properties changed by your light/dark styles */;
@media screen and (prefers-reduced-motion: reduce) {
transition-duration: none;
}
}
Transitions can also produce poor user experiences on devices that render changes slowly, for example, ones with e-ink screens. We can extend our “no motion condition” media query to account for that with the update media feature. If its value is slow, then we remove the transition-duration.
:root {
transition-duration: 200ms;
transition-property: /* properties changed by your light/dark styles */;
@media screen and (prefers-reduced-motion: reduce), (update: slow) {
transition-duration: 0s;
}
}
Let’s try out what we have so far in the following demo. Notice that, to work around color-scheme’s lack of transition support, I’ve explicitly styled the properties that should transition during theme changes.
See the Pen [CSS-only theme switcher (requires :has()) [forked]](https://codepen.io/smashingmag/pen/YzMVQja) by Henry.
Not bad! But what happens if the user refreshes the pages or navigates to another page? The reload effectively wipes out the user’s form selection, forcing the user to re-make the selection. That may be acceptable in some contexts, but it’s likely to go against user expectations. Let’s bring in JavaScript for a touch of progressive enhancement in the form of…
Persistence
Here’s a vanilla JavaScript implementation. It’s a naive starting point — the functions and variables aren’t encapsulated but are instead properties on window. You’ll want to adapt this in a way that fits your site’s conventions, framework, library, and so on.
When the user changes the color scheme from the menu, we’ll store the selected value in a new localStorage item called "preferredColorScheme". On subsequent page loads, we’ll check localStorage for the "preferredColorScheme" item. If it exists, and if its value corresponds to one of the form control options, we restore the user’s preference by programmatically updating the menu selection.
/*
* If a color scheme preference was previously stored,
* select the corresponding option in the color scheme preference UI
* unless it is already selected.
*/
function restoreColorSchemePreference() {
const colorScheme = localStorage.getItem(colorSchemeStorageItemName);
if (!colorScheme) {
// There is no stored preference to restore
return;
}
const option = colorSchemeSelectorEl.querySelector(`[value=${colorScheme}]`);
if (!option) {
// The stored preference has no corresponding option in the UI.
localStorage.removeItem(colorSchemeStorageItemName);
return;
}
if (option.selected) {
// The stored preference's corresponding menu option is already selected
return;
}
option.selected = true;
}
/*
* Store an event target's value in localStorage under colorSchemeStorageItemName
*/
function storeColorSchemePreference({ target }) {
const colorScheme = target.querySelector(":checked").value;
localStorage.setItem(colorSchemeStorageItemName, colorScheme);
}
// The name under which the user's color scheme preference will be stored.
const colorSchemeStorageItemName = "preferredColorScheme";
// The color scheme preference front-end UI.
const colorSchemeSelectorEl = document.querySelector("#color-scheme");
if (colorSchemeSelectorEl) {
restoreColorSchemePreference();
// When the user changes their color scheme preference via the UI,
// store the new preference.
colorSchemeSelectorEl.addEventListener("input", storeColorSchemePreference);
}
Let’s try that out. Open this demo (perhaps in a new window), use the menu to change the color scheme, and then refresh the page to see your preference persist:
See the Pen [CSS-only theme switcher (requires :has()) with JS persistence [forked]](https://codepen.io/smashingmag/pen/GRLmEXX) by Henry.
If your system color scheme preference is “light” and you set the demo’s color scheme to “dark,” you may get the light mode styles for a moment immediately after reloading the page before the dark mode styles kick in. That’s because CodePen loads its own JavaScript before the demo’s scripts. That is out of my control, but you can take care to improve this persistence on your projects.
Persistence Performance Considerations
Where things can get tricky is restoring the user’s preference immediately after the page loads. If the color scheme preference in localStorage is different from the user’s system-level color scheme preference, it’s possible the user will see the system preference color scheme before the page-level preference is restored. (Users who have selected the “System” option will never get that flash; neither will those whose system settings match their selected option in the form control.)
If your implementation is showing a “flash of inaccurate color theme”, where is the problem happening? Generally speaking, the earlier the scripts appear on the page, the lower the risk. The “best option” for you will depend on your specific stack, of course.
What About Browsers That Don’t Support :has()?
All major browsers support :has() today Lean into modern platforms if you can. But if you do need to consider legacy browsers, like Internet Explorer, there are two directions you can go: either hide or remove the color scheme picker for those browsers or make heavier use of JavaScript.
If you consider color scheme support itself a progressive enhancement, you can entirely hide the selection UI in browsers that don’t support :has():
@supports not selector(:has(body)) {
@media (prefers-color-scheme: dark) {
:root {
/* dark styles here */
}
}
#color-scheme {
display: none;
}
}
Otherwise, you’ll need to rely on a JavaScript solution not only for persistence but for the core functionality. Go back to that traditional event listener toggling a class or attribute.
The CSS-Tricks “Complete Guide to Dark Mode” details several alternative approaches that you might consider as well when working on the legacy side of things.
A fun fact about me is that my birthday is on Valentine’s Day. This year, I wanted to celebrate by launching a simple website that lets people receive anonymous letters through a personal link. The idea came up to me at the beginning of February, so I wanted to finish the project as soon as possible since time was of the essence.
Having that in mind, I decided not to do SSR/SSG with Gatsby for the project but rather go with a single-page application (SPA) using Vite and React — a rather hard decision considering my extensive experience with Gatsby. Years ago, when I started using React and learning more and more about today’s intricate web landscape, I picked up Gatsby.js as my render framework of choice because SSR/SSG was necessary for every website, right?
I used it for everything, from the most basic website to the most over-engineered project. I absolutely loved it and thought it was the best tool, and I was incredibly confident in my decision since I was getting perfect Lighthouse scores in the process.
It was like Gatsby got tougher to use with time because of lots of unaddressed issues: outdated dependencies, cold starts, slow builds, and stale plugins, to name a few. Starting a Gatsby project became tedious for me, and perfect Lighthouse scores couldn’t make up for that.
So, I’ve decided to stop using Gatsby as my go-to framework.
To my surprise, the Vite + React combination I mentioned earlier turned out to be a lot more efficient than I expected while maintaining almost the same great performance measures as Gatsby. It’s a hard conclusion to stomach after years of Gatsby’s loyalty.
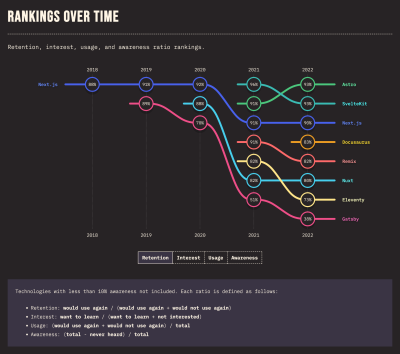
I mean, I still think Gatsby is extremely useful for plenty of projects, and I plan on talking about those in a bit. But Gatsby has undergone a series of recent unfortunate events after Netlify acquired it, the impacts of which can be seen in down-trending results from the most recent State of JavaScript survey. The likelihood of a developer picking up Gatsby again after using it for other projects plummeted from 89% to a meager 38% between 2019 and 2022 alone.
A ranking of the rendering frameworks retention. (Large preview)
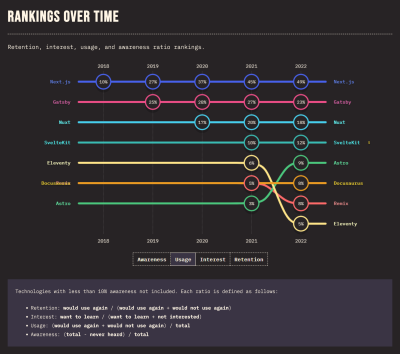
Although Gatsby was still the second most-used rendering framework as recently as 2022 — we are still expecting results from the 2023 survey — my prediction is that the decline will continue and dip well below 38%.
A ranking of the usage of the rendering framework. (Large preview)
Seeing as this is my personal farewell to Gatsby, I wanted to write about where, in my opinion, it went wrong, where it is still useful, and how I am handling my future projects.
I’d say it was the introduction of Gatsby Cloud in 2019, as Gatsby aimed at generating continuous revenue and solidifying its business model. Many (myself included) pinpoint Gatsby’s downfall to Gatsby Cloud, as it would end up cutting resources from the main framework and even making it harder to host in other cloud providers.
The core framework had been optimized in a way that using Gatsby and Gatsby Cloud together required no additional hosting configurations, which, as a consequence, made deployments in other platforms much more difficult, both by neglecting to provide documentation for third-party deployments and by releasing exclusive features, like incremental builds, that were only available to Gatsby users who had committed to using Gatsby Cloud. In short, hosting projects on anything but Gatsby Cloud felt like a penalty.
As a framework, Gatsby lost users to Next.js, as shown in both surveys and npm trends, while Gatsby Cloud struggled to compete with the likes of Vercel and Netlify; the former acquiring Gatsby in February of 2023.
“It [was] clear after a while that [Gatsby] weren’t winning the framework battle against Vercel, as a general purpose framework […] And they were probably a bit boxed in by us in terms of building a cloud platform.”
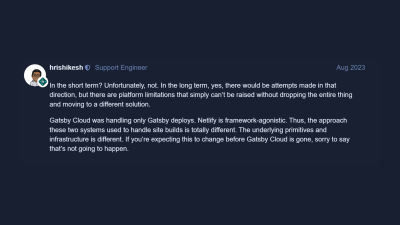
The Netlify acquisition was the last straw in an already tumbling framework haystack. The migration from Gatsby Cloud to Netlify wasn’t pretty for customers either; some teams were charged 120% more — or had incurred extraneous fees — after converting from Gatsby Cloud to Netlify, even with the same Gatsby Cloud plan they had! Many key Gatsby Cloud features, specifically incremental builds that reduced build times of small changes from minutes to seconds, were simply no longer available in Netlify, despite Kyle Mathews saying they would be ported over to Netlify:
“Many performance innovations specifically for large, content-heavy websites, preview, and collaboration workflows, will be incorporated into the Netlify platform and, where relevant, made available across frameworks.”
Netlify forum message from a support engineer. (Large preview)
That left no significant reason to remain with Gatsby. And I think this comment on the same thread perfectly sums up the community’s collective sentiment:
“Yikes. Huge blow to Gatsby Cloud customers. The incremental build speed was exactly why we switched from Netlify to Gatsby Cloud in the first place. It’s really unfortunate to be forced to migrate while simultaneously introducing a huge regression in performance and experience.”
Netlify’s acquisition also brought about a company restructuring that substantially reduced the headcount of Gatsby’s engineering team, followed by a complete stop in commit activities. A report in an ominous tweet by Astro co-founder Fred Schott further exacerbated concerns about Gatsby’s future.
“While we don’t plan for Gatsby to be where the main innovation in the framework ecosystem takes place, it will be a safe, robust and reliable choice to build production quality websites and e-commerce stores, and will gain new powers by ways of great complementary tools.”
— Matt Biilmann
He also shed light on Gatsby’s future focus:
“First, ensure stability, predictability, and good performance.
Second, give it new powers by strong integration with all new tooling that we add to our Composable Web Platform (for more on what’s all that, you can check out our homepage).
Third, make Gatsby more open by decoupling some parts of it that were closely tied to proprietary cloud infrastructure. The already-released Adapters feature is part of that effort.”
— Matt Biilmann
So, Gatsby gave up competing against Next.js on innovation, and instead, it will focus on keeping the existing framework clean and steady in its current state. Frankly, this seems like the most reasonable course of action considering today’s state of affairs.
Why Did People Stop Using Gatsby?
Yes, Gatsby Cloud ended abruptly, but as a framework independent of its cloud provider, other aspects encouraged developers to look for alternatives to Gatsby.
As far as I am concerned, Gatsby’s developer experience (DX) became more of a burden than a help, and there are two main culprits where I lay the blame: dependency hell and slow bundling times.
Dependency Hell
Go ahead and start a new Gatsby project:
gatsby new
After waiting a couple of minutes you will get your brand new Gatsby site. You’d rightly expect to have a clean slate with zero vulnerabilities and outdated dependencies with this out-of-the-box setup, but here’s what you will find in the terminal once you run npm audit:
That looks concerning — and it is — not so much from a security perspective but as an indication of decaying DX. As a static site generator (SSG), Gatsby will, unsurprisingly, deliver a static and safe site that (normally) doesn’t have access to a database or server, making it immune to most cyber attacks. Besides, lots of those vulnerabilities are in the developer tools and never reach the end user. Alas, relying on npm audit to assess your site security is a naive choice at best.
However, those vulnerabilities reveal an underlying issue: the whopping number of dependencies Gatsby uses is 168(!) at the time I’m writing this. For the sake of comparison, Next.js uses 16 dependencies. A lot of Gatsby’s dependencies are outdated, hence the warnings, but trying to update them to their latest versions will likely unleash a dependency hell full of additional npm warnings and errors.
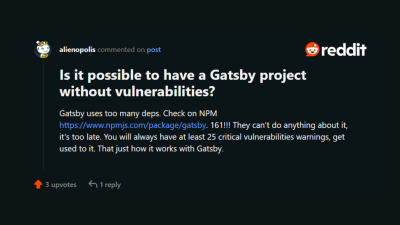
In a related subreddit from 2022, a user asked, “Is it possible to have a Gatsby site without vulnerabilities?”
The real answer is disappointing, but as of March 2024, it remains true.
A Gatsby site should work completely fine, even with that many dependencies, and extending your project shouldn’t be a problem, whether through its plugin ecosystem or other packages. However, when trying to upgrade any existing dependency you will find that you can’t! Or at least you can’t do it without introducing breaking changes to one of the 168 dependencies, many of which rely on outdated versions of other libraries that also cannot be updated.
It’s that inception-like roundabout of dependencies that I call dependency hell.
Slow Build And Development Times
To me, one of the most important aspects of choosing a development tool is how comfortable it feels to use it and how fast it is to get a project up and running. As I’ve said before, users don’t care or know what a “tech stack” is or what framework is in use; they want a good-looking website that helps them achieve the task they came for. Many developers don’t even question what tech stack is used on each site they visit; at least, I hope not.
With that in mind, choosing a framework boils down to how efficiently you can use it. If your development server constantly experiences cold starts and crashes and is unable to quickly reflect changes, that’s a poor DX and a signal that there may be a better option.
That’s the main reason I won’t automatically reach for Gatsby from here on out. Installation is no longer a trivial task; the dependencies are firing off warnings, and it takes the development server upwards of 30 seconds to boot. I’ve even found that the longer the server runs, the slower it gets; this happens constantly to me, though I admittedly have not heard similar gripes from other developers. Regardless, I get infuriated having to constantly restart my development server every time I make a change to gatsby-config.js, gatsby-node.js files, or any other data source.
This new reality is particularly painful, knowing that a Vite.js + React setup can start a server within 500ms thanks to the use of esbuild.
Esbuild time to craft a production bundle of 10 copies of the three.js library from scratch using default settings. (Image source: esbuild) (Large preview)
Running gatsby build gets worse. Build times for larger projects normally take some number of minutes, which is understandable when we consider all of the pages, data sources, and optimizations Gatsby does behind the scenes. However, even a small content edit to a page triggers a full build and deployment process, and the endless waiting is not only exhausting but downright distracting for getting things done. That’s what incremental builds were designed to solve and the reason many people switched from Netlify to Gatsby Cloud when using Gatsby. It’s a shame we no longer have that as an available option.
The moment Gatsby Cloud was discontinued along with incremental builds, the incentives for continuing to use Gatsby became pretty much non-existent. The slow build times are simply too costly to the development workflow.
What Gatsby Did Awesomely Well
I still believe that Gatsby has awesome things that other rendering frameworks don’t, and that’s why I will keep using it, albeit for specific cases, such as my personal website. It just isn’t my go-to framework for everything, mainly because Gatsby (and the Jamstack) wasn’t meant for every project, even if Gatsby was marketed as a general-purpose framework.
Here’s where I see Gatsby still leading the competition:
The GraphQL data layer.
In Gatsby, all the configured data is available in the same place, a data layer that’s easy to access using GraphQL queries in any part of your project. This is by far the best Gatsby feature, and it trivializes the process of building static pages from data, e.g., a blog from a content management system API or documentation from Markdown files.
Client performance.
While Gatsby’s developer experience is questionable, I believe it delivers one of the best user experiences for navigating a website. Static pages and assets deliver the fastest possible load times, and using React Router with pre-rendering of proximate links offers one of the smoothest experiences navigating between pages. We also have to note Gatsby’s amazing image API, which optimizes images to all extents.
The plugin ecosystem (kinda).
There is typically a Gatsby plugin for everything. This is awesome when using a CMS as a data source since you could just install its specific plugin and have all the necessary data in your data layer. However, a lot of plugins went unmaintained and grew outdated, introducing unsolvable dependency issues that come with dependency hell.
I briefly glossed over the good parts of Gatsby in contrast to the bad parts. Does that mean that Gatsby has more bad parts? Absolutely not; you just won’t find the bad parts in any documentation. The bad parts also aren’t deal breakers in isolation, but they snowball into a tedious and lengthy developer experience that pushes away its advocates to other solutions or rendering frameworks.
Do We Need SSR/SSG For Everything?
I’ll go on record saying that I am not replacing Gatsby with another rendering framework, like Next.js or Remix, but just avoiding them altogether. I’ve found they aren’t actually needed in a lot of cases.
Think, why do we use any type of rendering framework in the first place? I’d say it’s for two main reasons: crawling bots and initial loading time.
SEO And Crawling Bots
Most React apps start with a hollow body, only having an empty
alongside tags. The JavaScript code then runs in the browser, where React creates the Virtual DOM and injects the rendered user interface into the browser.
Over slow networks, users may notice a white screen before the page is actually rendered, which is just mildly annoying at best (but devastating at worst).
However, search engines like Google and Bing deploy bots that only see an empty page and decide not to crawl the content. Or, if you are linking up a post on social media, you may not get OpenGraph benefits like a link preview.
This was the case years ago, making SSR/SSG necessary for getting noticed by Google bots. Nowadays, Google can run JavaScript and render the content to crawl your website. While using SSR or SSG does make this process faster, not all bots can run JavaScript. It’s a tradeoff you can make for a lot of projects and one you can minimize on your cloud provider by pre-rendering your content.
Initial Loading Time
Pre-rendered pages load faster since they deliver static content that relieves the browser from having to run expensive JavaScript.
It’s especially useful when loading pages that are behind authentication; in a client-side rendered (CSR) page, we would need to display a loading state while we check if the user is logged in, while an SSR page can perform the check on the server and send back the correct static content. I have found, however, that this trade-off is an uncompelling argument for using a rendering framework over a CSR React app.
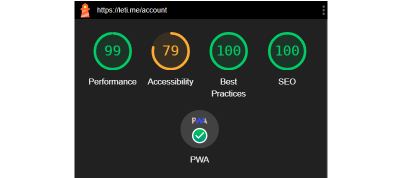
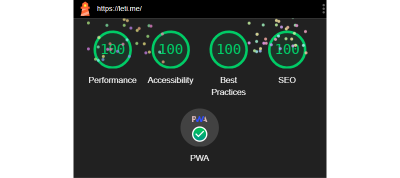
In any case, my SPA built on React + Vite.js gave me a perfect Lighthouse score for the landing page. Pages that fetch data behind authentication resulted in near-perfect Core Web Vitals scores.
Lighthouse scores for the app landing page. (Large preview)
Lighthouse scores for pages guarded by authentication. (Large preview)
What Projects Gatsby Is Still Good For
Gatsby and rendering frameworks are excellent for programmatically creating pages from data and, specifically, for blogs, e-commerce, and documentation.
Don’t be disappointed, though, if it isn’t the right tool for every use case, as that is akin to blaming a screwdriver for not being a good hammer. It still has good uses, though fewer than it could due to all the reasons we discussed before.
But Gatsby is still a useful tool. If you are a Gatsby developer the main reason you’d reach for it is because you know Gatsby. Not using it might be considered an opportunity cost in economic terms:
“Opportunity cost is the value of the next-best alternative when a decision is made; it’s what is given up.”
Imagine a student who spends an hour and $30 attending a yoga class the evening before a deadline. The opportunity cost encompasses the time that could have been dedicated to completing the project and the $30 that could have been used for future expenses.
As a Gatsby developer, I could start a new project using another rendering framework like Next.js. Even if Next.js has faster server starts, I would need to factor in my learning curve to use it as efficiently as I do Gatsby. That’s why, for my latest project, I decided to avoid rendering frameworks altogether and use Vite.js + React — I wanted to avoid the opportunity cost that comes with spending time learning how to use an “unfamiliar” framework.
Conclusion
So, is Gatsby dead? Not at all, or at least I don’t think Netlify will let it go away any time soon. The acquisition and subsequent changes to Gatsby Cloud may have taken a massive toll on the core framework, but Gatsby is very much still breathing, even if the current slow commits pushed to the repo look like it’s barely alive or hibernating.
I will most likely stick to Vite.js + React for my future endeavors and only use rendering frameworks when I actually need them. What are the tradeoffs? Sacrificing negligible page performance in favor of a faster and more pleasant DX that maintains my sanity? I’ll take that deal every day.
And, of course, this is my experience as a long-time Gatsby loyalist. Your experience is likely to differ, so the mileage of everything I’m saying may vary depending on your background using Gatsby on your own projects.
That’s why I’d love for you to comment below: if you see it differently, please tell me! Is your current experience using Gatsby different, better, or worse than it was a year ago? What’s different to you, if anything? It would be awesome to get other perspectives in here, perhaps from someone who has been involved in maintaining the framework.
In his seminal piece “The Market For Lemons”, renowned web crank Alex Russell lays out the myriad failings of our industry, focusing on the disastrous consequences for end users. This indignation is entirely appropriate according to the bylaws of our medium.
Frameworks factor highly in that equation, yet there can also be good reasons for front-end developers to choose a framework, or library for that matter: Dynamically updating web interfaces can be tricky in non-obvious ways. Let’s investigate by starting from the beginning and going back to the first principles.
Markup Categories
Everything on the web starts with markup, i.e. HTML. Markup structures can roughly be divided into three categories:
Static parts that always remain the same.
Variable parts that are defined once upon instantiation.
Variable parts that are updated dynamically at runtime.
For example, an article’s header might look like this:
«Hello World»
«123» backlinks
Variable parts are wrapped in «guillemets» here: “Hello World” is the respective title, which only changes between articles. The backlinks counter, however, might be continuously updated via client-side scripting; we’re ready to go viral in the blogosphere. Everything else remains identical across all our articles.
The article you’re reading now subsequently focuses on the third category: Content that needs to be updated at runtime.
Color Browser
Imagine we’re building a simple color browser: A little widget to explore a pre-defined set of named colors, presented as a list that pairs a color swatch with the corresponding color value. Users should be able to search colors names and toggle between hexadecimal color codes and Red, Blue, and Green (RGB) triplets. We can create an inert skeleton with just a little bit of HTML and CSS:
See the Pen [Color Browser (inert) [forked]](https://codepen.io/smashingmag/pen/RwdmbGd) by FND.
We’ve grudgingly decided to employ client-side rendering for the interactive version. For our purposes here, it doesn’t matter whether this widget constitutes a complete application or merely a self-contained island embedded within an otherwise static or server-generated HTML document.
Given our predilection for vanilla JavaScript (cf. first principles and all), we start with the browser’s built-in DOM APIs:
function renderPalette(colors) {
let items = [];
for(let color of colors) {
let item = document.createElement("li");
items.push(item);
let value = color.hex;
makeElement("input", {
parent: item,
type: "color",
value
});
makeElement("span", {
parent: item,
text: color.name
});
makeElement("code", {
parent: item,
text: value
});
}
let list = document.createElement("ul");
list.append(...items);
return list;
}
Note: The above relies on a small utility function for more concise element creation:
function makeElement(tag, { parent, children, text, ...attribs }) {
let el = document.createElement(tag);
if(text) {
el.textContent = text;
}
for(let [name, value] of Object.entries(attribs)) {
el.setAttribute(name, value);
}
if(children) {
el.append(...children);
}
parent?.appendChild(el);
return el;
}
You might also have noticed a stylistic inconsistency: Within the items loop, newly created elements attach themselves to their container. Later on, we flip responsibilities, as the list container ingests child elements instead.
Voilà: renderPalette generates our list of colors. Let’s add a form for interactivity:
The createField utility function encapsulates DOM structures required for input fields; it’s a little reusable markup component:
function createField(type, caption) {
let children = [
makeElement("span", { text: caption }),
makeElement("input", { type })
];
return makeElement("label", {
children: type === "checkbox" ? children.reverse() : children
});
}
Now, we just need to combine those pieces. Let’s wrap them in a custom element:
import { COLORS } from "./colors.js"; // an array of `{ name, hex, rgb }` objects
customElements.define("color-browser", class ColorBrowser extends HTMLElement {
colors = [...COLORS]; // local copy
connectedCallback() {
this.append(
renderControls(),
renderPalette(this.colors)
);
}
});
Henceforth, a element anywhere in our HTML will generate the entire user interface right there. (I like to think of it as a macro expanding in place.) This implementation is somewhat declarative1, with DOM structures being created by composing a variety of straightforward markup generators, clearly delineated components, if you will.
1 The most useful explanation of the differences between declarative and imperative programming I’ve come across focuses on readers. Unfortunately, that particular source escapes me, so I’m paraphrasing here: Declarative code portrays the what while imperative code describes the how. One consequence is that imperative code requires cognitive effort to sequentially step through the code’s instructions and build up a mental model of the respective result.
Interactivity
At this point, we’re merely recreating our inert skeleton; there’s no actual interactivity yet. Event handlers to the rescue:
Whenever a field changes, we update the corresponding instance variable (sometimes called one-way data binding). Alas, changing this internal state2 is not reflected anywhere in the UI so far.
2 In your browser’s developer console, check document.querySelector("color-browser").query after entering a search term.
Note that this event handler is tightly coupled to renderControls internals because it expects a checkbox and search field, respectively. Thus, any corresponding changes to renderControls — perhaps switching to radio buttons for color representations — now need to take into account this other piece of code: action at a distance! Expanding this component’s contract to include field names could alleviate those concerns.
We’re now faced with a choice between:
Reaching into our previously created DOM to modify it, or
Recreating it while incorporating a new state.
Rerendering
Since we’ve already defined our markup composition in one place, let’s start with the second option. We’ll simply rerun our markup generators, feeding them the current state.
Note: I’m partial to the bouncer pattern. Toggling color representations is left as an exercise for the reader. You might pass this.rgb into renderPalette and then populate with either color.hex or color.rgb, perhaps employing this utility:
Entering a query seems impossible as the input field loses focus after a change takes place, leaving the input field empty. However, entering an uncommon character (e.g. “v”) makes it clear that something is happening: The list of colors does indeed change.
The reason is that our current do-it-yourself (DIY) approach is quite crude: #render erases and recreates the DOM wholesale with each change. Discarding existing DOM nodes also resets the corresponding state, including form fields’ value, focus, and scroll position. That’s no good!
Incremental Rendering
The previous section’s data-driven UI seemed like a nice idea: Markup structures are defined once and re-rendered at will, based on a data model cleanly representing the current state. Yet our component’s explicit state is clearly insufficient; we need to reconcile it with the browser’s implicit state while re-rendering.
Sure, we might attempt to make that implicit state explicit and incorporate it into our data model, like including a field’s value or checked properties. But that still leaves many things unaccounted for, including focus management, scroll position, and myriad details we probably haven’t even thought of (frequently, that means accessibility features). Before long, we’re effectively recreating the browser!
We might instead try to identify which parts of the UI need updating and leave the rest of the DOM untouched. Unfortunately, that’s far from trivial, which is where libraries like React came into play more than a decade ago: On the surface, they provided a more declarative way to define DOM structures4 (while also encouraging componentized composition, establishing a single source of truth for each individual UI pattern). Under the hood, such libraries introduced mechanisms5 to provide granular, incremental DOM updates instead of recreating DOM trees from scratch — both to avoid state conflicts and to improve performance6.
The bottom line: If we want to encapsulate markup definitions and then derive our UI from a variable data model, we kinda have to rely on a third-party library for reconciliation.
Actus Imperatus
At the other end of the spectrum, we might opt for surgical modifications. If we know what to target, our application code can reach into the DOM and modify only those parts that need updating.
Regrettably, though, that approach typically leads to calamitously tight coupling, with interrelated logic being spread all over the application while targeted routines inevitably violate components’ encapsulation. Things become even more complicated when we consider increasingly complex UI permutations (think edge cases, error reporting, and so on). Those are the very issues that the aforementioned libraries had hoped to eradicate.
In our color browser’s case, that would mean finding and hiding color entries that do not match the query, not to mention replacing the list with a substitute message if no matching entries remain. We’d also have to swap color representations in place. You can probably imagine how the resulting code would end up dissolving any separation of concerns, messing with elements that originally belonged exclusively to renderPalette.
As a once wise man once said: That’s too much knowledge!
Things get even more perilous with form fields: Not only might we have to update a field’s specific state, but we would also need to know where to inject error messages. While reaching into renderPalette was bad enough, here we would have to pierce several layers: createField is a generic utility used by renderControls, which in turn is invoked by our top-level ColorBrowser.
If things get hairy even in this minimal example, imagine having a more complex application with even more layers and indirections. Keeping on top of all those interconnections becomes all but impossible. Such systems commonly devolve into a big ball of mud where nobody dares change anything for fear of inadvertently breaking stuff.
Conclusion
There appears to be a glaring omission in standardized browser APIs. Our preference for dependency-free vanilla JavaScript solutions is thwarted by the need to non-destructively update existing DOM structures. That’s assuming we value a declarative approach with inviolable encapsulation, otherwise known as “Modern Software Engineering: The Good Parts.”
As it currently stands, my personal opinion is that a small library like lit-html or Preact is often warranted, particularly when employed with replaceability in mind: A standardized API might still happen! Either way, adequate libraries have a light footprint and don’t typically present much of an encumbrance to end users, especially when combined with progressive enhancement.
I don’t wanna leave you hanging, though, so I’ve tricked our vanilla JavaScript implementation to mostly do what we expect it to:
See the Pen [Color Browser [forked]](https://codepen.io/smashingmag/pen/vYPwBro) by FND.
Front-end development seemed simpler in the early 2000s, didn’t it? The standard website consisted mostly of static pages made of HTML and CSS seasoned with a pinch of JavaScript and jQuery. I mean, who doesn’t miss the cross-browser compatibility days, right?
Fast forward to today, and it looks like a parallel universe is taking place with an overwhelming number of choices. Which framework should you use for a new project? Perhaps more established ones like React, Angular, Vue, Svelte, or maybe the hot new one that came out last month? Each framework comes with its unique ecosystem. You also need to decide whether to use TypeScript over vanilla JavaScript and choose how to approach server-side rendering (or static site generation) with meta-frameworks like Next, Nuxt, or Gatsby. And we can’t forget about unit and end-to-end testing if you want a bug-free web app. And we’ve barely scratched the surface of the front-end ecosystem!
But has it really gotten more complex to build websites? A lot of the frameworks and tooling we reach for today were originally crafted for massive projects. As a newcomer, it can be frightening to have so many to consider, almost creating a fear of missing out that we see exploited to sell courses and tutorials on the new hot framework that you “cannot work without.”
All this gives the impression that web development has gotten perhaps too complex. But maybe that is just an exaggeration? In this article, I want to explore those claims and find out if web development really is that complex and, most importantly, how we can prevent it from getting even more difficult than we already perceive it to be.
How It Was Before
As someone who got into web development after 2010, I can’t testify to my own experience about how web development was from the late 1990s through the 2000s. However, even fifteen years ago, learning front-end development was infinitely simpler, at least to me. You could get a website started with static HTML pages, minimal CSS for styling, and a sprinkle of JavaScript (and perhaps a touch of jQuery) to add interactive features, from toggled sidebars to image carousels and other patterns. Not much else was expected from your average developer beyond that — everything else was considered “going the extra mile.” Of course, the awesome native CSS and JavaScript features we have today weren’t around back then, but they were also unnecessary for what was considered best practice in past years.
Large and dynamic web apps certainly existed back then — YouTube and Facebook, to name a couple — but they were developed by massive companies. No one was expected to re-create that sort of project on their own or even a small team. That would’ve been the exception rather than the norm.
I remember back then, tend to worry more about things like SEO and page optimization than how my IDE was configured, but only to the point of adding meta tags and keywords because best practices didn’t include minifying all your assets, three shaking your code, caching your site on edge CDNs, or rendering your content on the server (a problem created by modern frameworks along hydration). Other factors like accessibility, user experience, and responsive layouts were also largely overlooked in comparison to today’s standards. Now, they are deeply analyzed and used to boost Lighthouse scores and impress search engine algorithms.
The web and everything around it changed as more capabilities were added and more and more people grew to depend on it. We have created new solutions, new tools, new workflows, new features, and whatever else new that is needed to cater to a bigger web with even bigger needs.
The web has always had its problems in the past that were worthy of fixing: I absolutely don’t miss tables and float layouts, along with messy DOM manipulation. This post isn’t meant to throw shade on new advances while waxing nostalgic about the good days of the “old wild web.” At the same time, though, yesterday’s problems seem infinitely simpler than those we face today.
JavaScript Frameworks
JavaScript frameworks, like Angular and React, were created by Google and Facebook, respectively, to be used in their own projects and satisfy the needs that only huge web-based companies like them have. Therein lies the main problem with web complexity: JavaScript frameworks were originally created to sustain giant projects rather than smaller ones. Many developers vastly underestimate the amount of time it takes to build a codebase that is reliable and maintainable with a JavaScript framework. However, the alternative of using vanilla JavaScript was worse, and jQuery was short for the task. Vanilla JavaScript was also unable to evolve quickly enough to match our development needs, which changed from simple informative websites to dynamic apps. So, many of us have quickly adopted frameworks to avoid directly mingling with JavaScript and its messy DOM manipulation.
Back-end development is a completely different topic, subject to its own complexities. I only want to focus on front-end development because that is the discipline that has perhaps overstepped its boundaries the most by bleeding into traditional back-end concerns.
Stacks Getting Bigger
It was only logical for JavaScript frameworks to grow in size over time. The web is a big place, and no one framework can cover everything. But they try, and the complexity, in turn, increases. A framework’s size seems to have a one-to-one correlation with its complexity.
But the core framework is just one piece of a web app. Several other technologies make up what’s known as a tech “stack,” and with the web gaining more users and frameworks catering to their needs, tech stacks are getting bigger and bigger. You may have seen popular stacks such as MEAN (MongoDB, Express, Angular, and Node) or its React (MERN) and Vue (MEVN) variants. These stacks are marketed as mature, test-proofed foundations suitable for any front-end project. That means the advertised size of a core framework is grossly underestimated because they rely on other micro-frameworks to ensure highly reliable architectures, as you can see in stackshare.io. Besides, there isn’t a one-size-fits-all stack; the best tool has always depended — and will continue to depend — on the needs and goals of your particular project.
This means that each new project likely requires a unique architecture to fulfill its requirements. Giant tech companies need colossal architectures across all their projects, and their stacks are highly engineered accordingly to secure scalability and maintenance. They also have massive customer bases, so maintaining a large codebase will be easier with more revenue, more engineers, and a clearer picture of the problem. To minimize waste, the tech stacks of smaller companies and projects can and should be minimized not only to match the scale of their needs but to the abilities of the developers on the team as well.
The idea that web development is getting too complex comes from buying into the belief that we all have the same needs and resources as giant enterprises.
“
Trying to imitate their mega stacks is pointless. Some might argue that it’s a sacrifice we have to make for future scalability and maintenance, but we should focus first on building great sites for the user without worrying about features users might need in the future. If what we are building is worth pursuing, it will reach the point where we need those giant architectures in good time. Cross that bridge when we get there. Otherwise, it’s not unlike wearing Shaquille O’Neal-sized sneakers in hopes of growing into them. They might not even last until then if it happens at all!
We must remember that the end-user experience is the focus at the end of the day, and users neither care about nor know what stack we use in our apps. What they care about is a good-looking, useful website where they can accomplish what they came for, not the technology we use to achieve it. This is how I’ve come to believe that web development is not getting more complex. It’s developers like us who are perpetuating it by buying into solutions for problems that do not need to be solved at a certain scale.
Let me be really clear: I am not saying that today’s web development is all bad. Indeed, we’ve realized a lot of great features, and many of them are thanks to JavaScript frameworks that have pushed for certain features. jQuery had that same influence on JavaScript for many, many years.
We can still create minimum viable products today with minimal resources. No, those might not make people smash the Like button on your social posts, but they meet the requirements, nothing more and nothing less. We want bigger! Faster! Cheaper! But we can’t have all three.
If anything, front-end development has gotten way easier thanks to modern features that solve age-old development issues, like the way CSS Flexbox and Grid have trivialized layouts that used to require complex hacks involving floats and tables. It’s the same deal with JavaScript gaining new ways to build interactions that used to take clever workarounds or obtuse code, such as having the Intersection Observer API to trivialize things like lazy loading (although HTML has gained its own features in that area, too).
We live in this tension between the ease of new platform features and the complexity of our stacks.
“
Do We Need A JavaScript Framework For Everything?
Each project, regardless of its simplicity, desperately needs a JavaScript framework. A project without a complex framework is like serving caviar on a paper plate.
At least, that’s what everyone seems to think. But is that actually true? I’d argue on the contrary. JavaScript frameworks are best used on bigger applications. If you’re working on a smaller project, a component-based framework will only complicate matters, making you split your website into a component hierarchy that amounts to overkill for small projects.
The idea of needing a framework for everything has been massively oversold. Maybe not directly, but you unconsciously get that feeling whenever a framework’s name pops in, as Edge engineer Alex Russell eloquently expresses in his article, “The Market For Lemons”:
“These technologies were initially pitched on the back of “better user experiences” but have utterly failed to deliver on that promise outside of the high-management-maturity organisations in which they were born. Transplanted into the wider web, these new stacks have proven to be expensive duds.”
— Alex Russell
Remember, the purpose of a framework is to simplify your life and save time. If the project you’re working on is smaller, the time you supposedly save is likely overshadowed by the time you spend either setting up the framework or making it work with the rest of the project. A framework can help make bigger web apps more interactive and dynamic, but there are times when a framework is a heavy-handed solution that actually breeds inefficient workflows and introduces technical debt.
Step back and think about this: Are HTML, CSS, and a touch of JavaScript enough to build your website or web application? If so, then stick with those. What I am afraid of is adding complexity for complexity’s sake and inadvertently raising the barrier to entry for those coming into web development. We can still accomplish so much with HTML and CSS alone, thanks again to many advances in the last decade. But we give the impression that they are unsuitable for today’s web consumption and need to be enhanced.
Knowing Everything And Nothing At The Same Time
The perceived standard that teams must adopt framework-centered architectures puts a burden not only on the project itself but on a developer’s well-being, too. As mentioned earlier, most teams are unable to afford those architectures and only have a few developers to maintain them. If we undermine what can be achieved with HTML and CSS alone and set the expectations that any project — regardless of size — needs to have a bleeding edge stack, then the weight to meet those expectations falls on the developer’s shoulders, with the great responsibility of being proficient in all areas, from the server and database to front end, to design, to accessibility, to performance, to testing, and it doesn’t stop. It’s what has been driving “The Great Divide” in front-end development, which Chris Coyier explains like this:
“The divide is between people who self-identify as a (or have the job title of) front-end developer yet have divergent skill sets. On one side, an army of developers whose interests, responsibilities, and skillsets are heavily revolved around JavaScript. On the other, an army of developers whose interests, responsibilities, and skillsets are focused on other areas of the front end, like HTML, CSS, design, interaction, patterns, accessibility, and so on.”
— Chris Coyier
Under these expectations, developers who focus more on HTML, CSS, design, and accessibility rather than the latest technology will feel less valued in an industry that appears to praise those who are concerned with the stack. What exactly are we saying when we start dividing responsibilities in terms of “full-stack development” or absurd terms like “10x development”? A while back, Brad Frost began distinguishing these divisions as “front-of-the-front-end” and “back-of-the-front-end”.
Mandy Michael explains what impact the chase for “full-stack” has had on developers trying to keep up:
“The worst part about pushing the “know everything” mentality is that we end up creating an industry full of professionals suffering from burnout and mental illness. We have people speaking at conferences about well-being, imposter syndrome, and full-stack anxiety, yet despite that, we perpetuate this idea that people have to know everything and be amazing at it.”
— Mandy Michael
This isn’t the only symptom of adopting heavy-handed solutions for what “vanilla” HTML, CSS, and JavaScript already handle nicely. As the expectations for what we can do as front-end developers grow, the learning curve of front-end development grows as well. Again, we can’t learn and know everything in this vast discipline. But we tell ourselves we have to, and thanks to this mentality, it’s unfortunately common to witness developers who may be extremely proficient with a particular framework but actually know and understand little of the web platform itself, like HTML semantics and structure.
The fact that many budding developers tend to jump straight into frameworks at the expense of understanding the basics of HTML and CSS isn’t a new worry, as Rachel Andrew discussed back in 2019:
“That’s the real entry point here, and yes, in 2019, they are going to have to move on quickly to the tools and techniques that will make them employable, if that is their aim. However, those tools output HTML and CSS in the end. It is the bedrock of everything that we do, which makes the devaluing of those with real deep skills in those areas so much more baffling.”
— Rachel Andrew
And I want to clarify yet again that modern Javascript frameworks and libraries aren’t inherently bad; they just aren’t designed to replace the web platform and its standards. But we keep pushing them like we want them to!
The Consequences Of Vendor Lock-In
“Vendor lock-in” happens when we depend too deeply on proprietary products and services to the extent that switching to other products and services becomes a nearly impossible task. This often occurs when cloud services from a particular company are deeply integrated into a project. It’s an issue, especially in cloud computing, since moving databases once they are set up is expensive and lengthy.
Vendor lock-in in web development has traditionally been restricted to the back end, like with cloud services such as AWS or Firebase; the front-end framework, meanwhile, was a completely separate concern. That said, I have noticed a recent trend where vendor lock-in is reaching into meta-frameworks, too. With the companies behind certain meta-frameworks offering hosting services for their own products, swapping hosts is increasingly harder to do (whether the lock-in is designed intentionally or not). Of course, companies and developers will be more likely to choose the hosting service of the company that made a particular framework used on their projects — they’re the experts! — but that only increases the project’s dependency on those vendors and their services.
A clear example is the relationship between Next and Vercel, the parent cloud service for Next. With the launch of Next 13, it has become increasingly harder to set up a Next project outside of Vercel, leading to projects like Open Next, which says right on its website that “[w]hile Vercel is great, it’s not a good option if all your infrastructure is on AWS. Hosting it in your AWS account makes it easy to integrate with your backend [sic]. And it’s a lot cheaper than Vercel.” Fortunately, the developers’ concerns have been heard, and Next 14 brings clarity on how to self-host Next on a Node server.
Another example is Gatsby and Gatsby Cloud. Gatsby has always offered helpful guides and alternative hosting recommendations, but since the launch of Gatsby Cloud in 2019, the main framework has been optimized so that using Gatsby and Gatsby Cloud together requires no additional hosting configurations. That’s fantastic if you adopt both, but it’s not so great if all you need is one or the other because integrating the framework with other hosts — and vice versa — is simply harder. It’s as if you are penalized for exercising choice.
And let’s not forget that no team expected Netlify to acquire Gatsby Cloud in February 2023. This is a prime case where the vendor lock-in problem hits everybody because converting from one site to another comes at a cost. Some teams were charged 120% more after converting from Gatsby Cloud to Netlify — even with the same plan they had with Gatsby Cloud!
What’s the solution? The common answer I hear is to stop using paid cloud services in favor of open-sourced alternatives. While that’s great and indeed a viable option for some projects, it fails to consider that an open-source project may not meet the requirements needed for a given app.
And even then, open-source software depends on the community of developers that maintain and update the codebase with little to no remuneration in exchange. Further, open source is equally prone to locking you into certain solutions that are designed to solve a deficiency with the software.
There are frameworks and libraries, of course, that are in no danger of being abandoned. React is a great example because it has an actively engaged community behind it. But you can’t have the same assurance with each new dependency you add to a project. We can’t simply keep installing more packages and components each time we spot a weak spot in the dependency chain, especially when a project is perfectly suited for a less complex architecture that properly leverages the web platform.
Choosing technology for your stack is an exercise of picking your own poison. Either choose a paid service and be subject to vendor lock-in in the future, or choose an open-source one and pray that the community continues to maintain it.
“
Those are virtually the only two choices. Many of the teams I know or have worked on depend on third-party services because they cannot afford to develop them on their own; that’s a luxury that only massive companies can afford. It’s a problem we have to undergo when starting a new project, but one we can minimize by reducing the number of dependencies and choosing wisely when we have to.
Each Solution Introduces A New Problem
Why exactly have modern development stacks gotten so large and complex? We can point a finger at the “Development Paradox.” With each new framework or library, a new problem crops up, and time-starved developers spend months developing a new tool to solve that problem. And when there isn’t a problem, don’t worry — we will create one eventually. This is a feedback loop that creates amazing solutions and technologies but can lead to over-engineered websites if we don’t reign it in.
This reminds me of the famous quote:
“The plain fact is that if you don’t have a problem, you create one. If you don’t have a problem, you don’t feel that you are living.”
— U.G. Krishnamurti
Let’s look specifically at React. It was originally created by Facebook for Facebook to develop more dynamic features for users while improving Facebook’s developer experience.
Since React was open-sourced in 2013 (and nearly re-licensed in 2017, if it weren’t for the WordPress community), hundreds of new utilities have been created to address various React-specific problems. How do you start a React project? There’s Create React App and Vite. Do you need to enhance your state management? There is Redux, among other options. Need help creating forms? There is a React Hook Form. And perhaps the most important question: Do you need server-side rendering? There’s Next, Remix, or Gatsby for that. Each solution comes with its own caveats, and developers will create their own solutions for them.
It may be unfair to pick on React since it considers itself a library, not a framework. It’s inevitably prone to be extended by the community. Meanwhile, Angular and Vue are frameworks with their own community ecosystems. And this is the tip of the iceberg since there are many JavaScript frameworks in the wild, each with its own distinct ideology and dependencies.
Again, I don’t want you to get the wrong idea. I love that new technologies emerge and find it liberating to have so many options. But when building something as straightforward as a webpage or small website — which some have started referring to as “multi-page applications” — we have to draw a line that defines how many new technologies we use and how reliable they are. We’re quite literally mashing together third-party code written by various third-party developers. What could go wrong? Please don’t answer that.
Remember that our users don’t care what’s in our stacks. They only see the final product, so we can save ourselves from working on unnecessary architectures that aren’t appreciated outside of development circles. It may seem counterintuitive in the face of advancing technology, but knowing that the user doesn’t care about what goes behind the scenes and only sees the final product will significantly enhance our developer experience and free you from locked dependencies. Why fix something that isn’t broken?
How Can We Simplify Our Codebases?
We’ve covered several reasons why web development appears to be more complex today than in years past, but blaming developers for releasing new utilities isn’t an accurate portrayal of the real problem. After all, when developing a site, it’s not like we are forced to use each new technology that enters the market. In fact, many of us are often unaware of a particular library and only learn about it when developing a new feature. For example, if we want to add toast notifications to our web app, we will look for a library like react-toastify rather than some other way of building them because it “goes with” that specific library. It’s worth asking whether the app needs toast notifications at all if they introduce new dependencies.
Imagine you are developing an app that allows users to discover, review, and rate restaurants in their area. The app needs, at a bare minimum, information about each restaurant, a search tool to query them, and an account registration flow with authentication to securely access the account. It’s easy to make assumptions about what a future user might need in addition to these critical features. In many cases, a project ends up delayed because we add unnecessary features like SSR, notifications, offline mode, and fancy animations — sometimes before the app has even converted its first registered user!
I believe we can boil down the complexity problem to personal wishes and perceived needs rather than properly scoping a project based on user needs and experiences.
That level of scope creep can easily turn into an over-engineered product that will likely never see the light of launching.
What can we do to simplify our own projects? The following advice is relevant when you have control over your project, either because it’s a personal one, it’s a smaller one for a smaller team, or you have control over the decisions in whatever size organization you happen to be in.
The hardest and most important step is having a sense of detection when your codebase is getting unnecessarily complicated. I deem it the hardest step because there is no certainty of what the requirements are or what the user needs; we can only make assumptions. Some are obvious, like assuming the user will need a way to log into the app. Others might be unclear, like whether the app should have private messaging between users. Others are still far-fetched, like believing users need extremely low latency in an e-commerce page. Other features are in the “nice to have” territory.
That is regarding the user experience, but the same questions emerge on the development side:
Should we be using a CSS preprocessor or a CSS framework, or can we achieve it using only CSS modules?
Is vanilla JavaScript enough, or are we going to add TypeScript?
Does the app need SSR, SSG, or a hybrid of the two?
Should we implement Redis on the back end for faster database queries, or is that too much scope for the work?
Should we be implementing end-to-end testing or unit tests?
These are valid questions that should be considered when developing a site, but they can distract us from our main focus: getting things done.
“Done is better than perfect.”
— Sheryl Sandberg
And, hey, even the largest and most sophisticated apps began as minimal offerings that iterated along the way.
First versions of Amazon, Facebook, Google and Twitter. (Large preview)
We also ought to be asking ourselves what would happen if a particular feature or dependency isn’t added to the project. If the answer is “nothing,” then we should be shifting our attention to something else.
Another question worth asking: “Why are we choosing to add [X]?” Is it because that’s what is popular at the moment, or because it solves a problem affecting a core feature? Another aspect to take into consideration is how familiar we are with certain technologies and give preference to those we know and can start using them right away rather than having to stop and learn the ins and outs of a new framework.
Choose the right tool for the job, which is going to be the one that meets the requirements and fits your mental model. Focus less on a library’s popularity and scalability but rather on getting your app to the point where it needs to scale in the first place.
Conclusion
It’s incredibly difficult to not over-engineer web apps given current one-size-fits-all and fear-of-missing-out mentalities. But we can be more conscious of our project goals and exercise vigilance in guarding our work against scope creep. The same can be applied to the stack we use, making choices based on what is really needed rather than focusing purely on what everyone else is using for their particular work.
After reading the word “framework” exactly 48 times in this article, can we now say the web is getting too complex? It has been complex by nature since its origins, but complexity doesn’t translate to “over-engineered” web apps. The web isn’t intrinsically over-engineered, and we only have ourselves to blame for over-engineering our projects with overly-wrought solutions for perceived needs.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}